
阿里妹导读
一、省流版简介
通过本篇文章,你可以了解并实践通过【ComfyUI】构建自己的【文生图】和【文生动图】工作流,本文所有操作环境和硬件都基于公司所发工作电脑,模型都基于网络开源,无需自己训练调参。(不过如果你有更强悍的电脑,自己有自己的模型就更好了)。同时我也会给出我自己简单搭建的【workflow】给大家,方便大家快速使用。

二、安装
需要:
PyTorch 是一种用于构建深度学习模型的功能完备框架,是一种通常用于图像识别和语言处理等应用程序的机器学习。使用 Python 编写,因此对于大多数机器学习开发者而言,学习和使用起来相对简单。PyTorch 的独特之处在于,它完全支持 GPU,并且使用反向模式自动微分技术,因此可以动态修改计算图形。这使其成为快速实验和原型设计的常用选择。
我是使用conda来进行安装的,没有conda的可以先进行安装:
然后通过conda工具来安装pytorch:
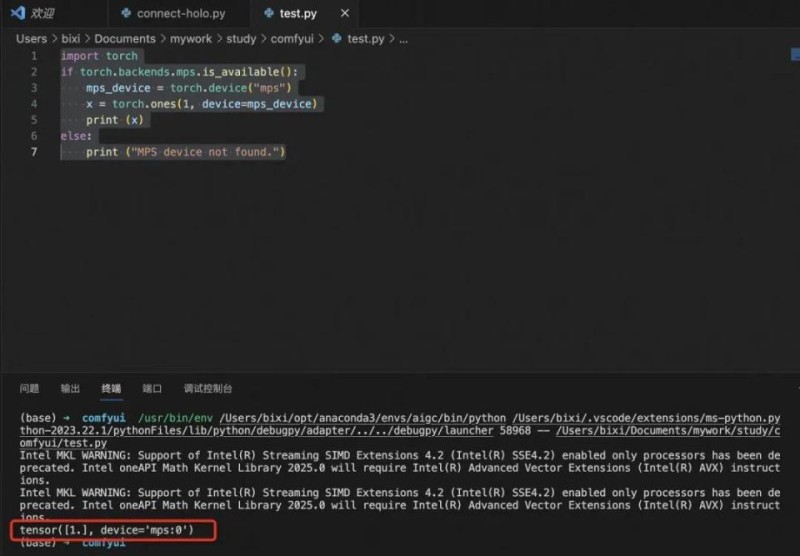
最后运行一个python脚本来判断:
如果安装正确,会有如下输出:
使用 git 命令下载代码库到本地:
然后cd到仓库主目录,安装依赖:
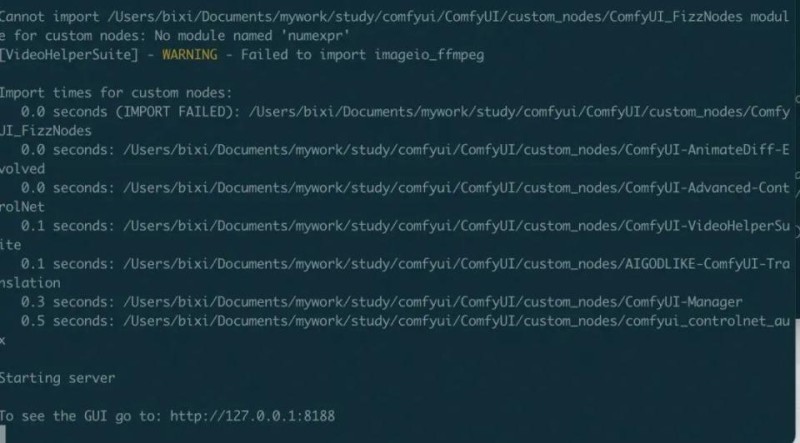
然后运行程序,检测下载安装是否正常:
可以看到如果安装正常,会提示你服务已经部署在了本地地址:http://127.0.0.1:8188
请求本地地址,即可访问ComfyUI:
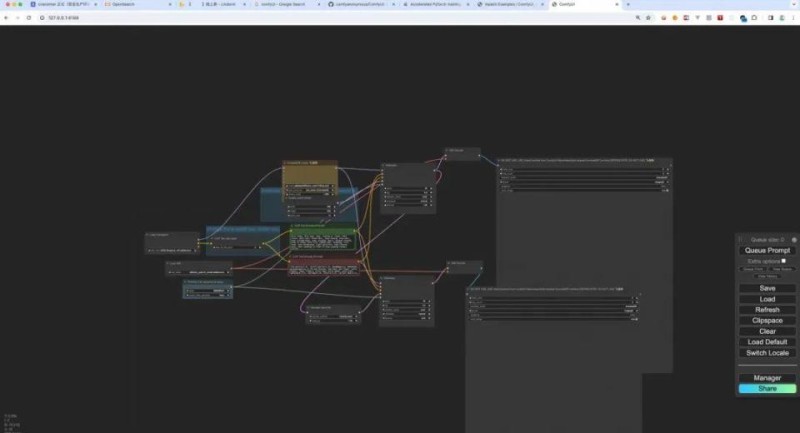
但是现在,你还没有配套部署任何的模型,所以此时是跑不起来的。
我自己在用两个模型下载的网站,两个都被墙了,需要大家自行科学上网:
HuggingFace:https://huggingface.co/
civitai:https://civitai.com/models
个人体验下来,HuggingFace更权威更偏学术一些,civital下载更快更偏娱乐一些(civital上有很多有趣的模型,玩起来还是很不错)。
模型的话,一般会存在两种后缀格式:
在下载完模型后,我们需要将模型导入到 ComfyUI 的 models 目录下,这样 ComfyUI 才能够加载到对应的模型。
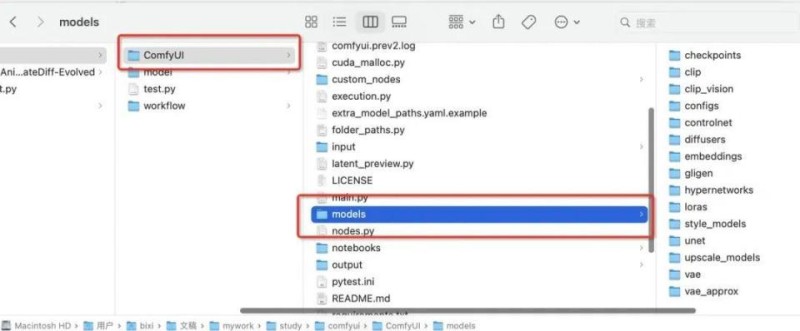
三、使用
1. Comfy界面详解和基础使用
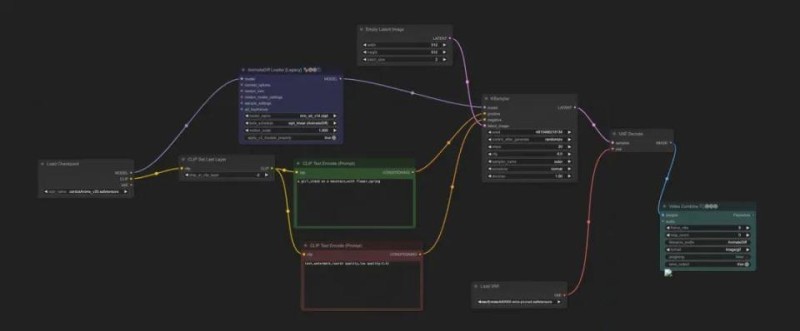
ComfyUI是通过一个个Node,加上Node与Node之间的链接,完成输入输出,并最终串联起整个AI生成的工作流(workflow)。
以【Clip Text Encode(Prompt)】节点为例:
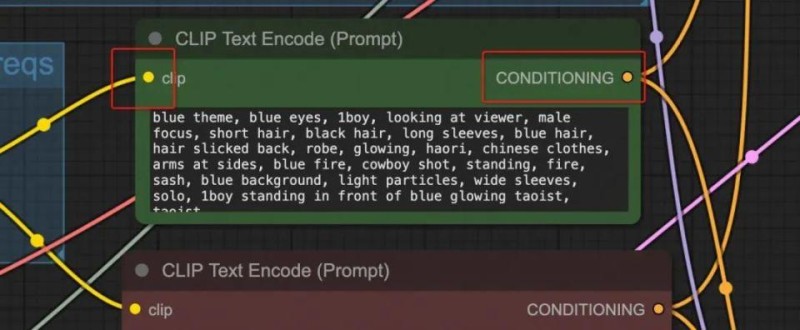
其左侧端点是 Input(输入)端,右侧是 Output(输出)端,节点里还会有一些配置项,这些配置项我会称其为 Parameter(参数),参数是可编辑和调整的。通过将连线输入或输出到不同Node,可以串起不同的工作流。
1.2.1. Load Checkpoint
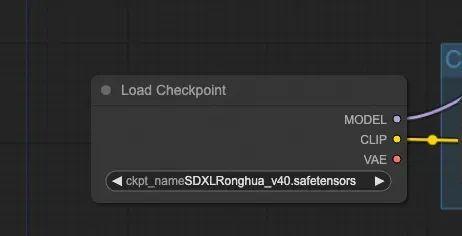
【Load Checkpoint】,顾名思义,就是加载模型用的。从节点的右边输出端点可以看出,Checkpoint 包含了三个部分:MODEL、CLIP 还有 VAE,这三部分其实就是Stable Diffusion 的模型运行的三大步骤,可以说这个节点是所有 Workflow 的起点。
三大步骤:

类似于降噪然后蚀刻的过程,可以参考 Midjourney 图片生成的过程:由暗变清晰:
1.2.2. CLIP Text Encode(Prompt) Node
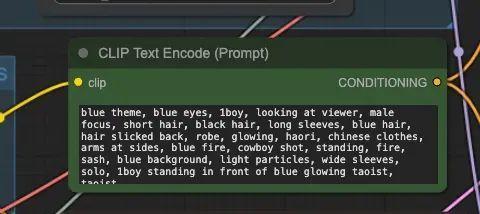
CLIP Text Enocde 节点,CLIP 全称是 Contrastive Language-Image Pre-training,即对比文本图像预训练。这个节点主要是输入 Prompt。一般会有两个这样的节点,一个是正向的 Prompt,列你希望在图片中看到的内容;另一个是负向的 Prompt,列你不希望在图片中出现的内容。
一般说来,写 Stable Diffusion 的 prompt 有几个原则:
另外,还有个小技巧,你可以输入 (keyword:weight) 方式来控制关键词的权重,比如 (hight building: 1.2 ) 就意味着 hight building 的权重变高,如果填写的权重数小于 1,则意味着这个词的权重会变低,生成的图与这个词更不相关。
1.2.3. Empty Latent Image Node
这是【潜空间】图像节点。如果你需要调整最终生成的图片的大小,就需要调整 width(宽)、height(高)这两个值。而 batch_size 则是设置每次运行时生成的图片数量,比如你将这个设置成了 4,就意味着每次会生成 4 张图。
1.2.4. Save Image Node
完成图片生成后,对着图片点击右键,会看到「Save Image」的选项,点击此按钮就可以下载生成好的图片。节点里的输入框,则是设置图片名称的前缀。比如默认是 ComfyUI,那就意味着你保存的图片的文件名是 ComfyUI 开头,后面跟着一串数字。
1.2.5. KSampler Node
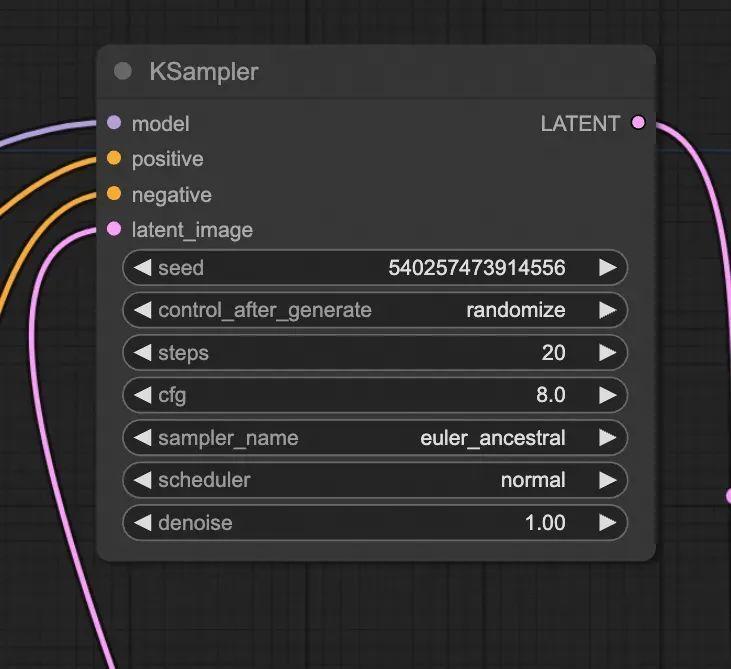
KSampler 包含以下参数:
连线是具有规则的:
其实更好的做法是实操起来,报错提示还是蛮清晰的,根据错误去改进自己的工作流。
2. 进阶使用
总结基于Stable Diffusion进行图片生成的过程,就是【降噪】,在降噪的过程中,还有一个重要的环节就是【Noise Predictor】。
Noise Predictor 是如何工作的呢?简单理解就是进行了一系列的运算,运算所使用到的算法被称为 UNet 算法。UNet 的算法大概是这样的:

左侧是输入,右侧是输出,数据输入后会经过一些列的运算,图中的长条的柱子就是一步运算。我们可以通过改变柱子里的参数权重,从而改变输出结果,最终改变生成图片的效果。但改变每根柱子里的结果相对比较复杂。
于是研究人员就开始寻找一种更简单的方法,最终他们发现,如果将参数注入到每一层函数中,也能达到改变图片的效果,这个方法就是 LoRA(Low-Rank Adaptation)。
LoRA 是在不破坏任何一层函数,而是将参数注入到原有的每一层中。这样的好处是不破坏原有的模型,即插即用,并且模型的大小也比较小。可视化的效果如下:
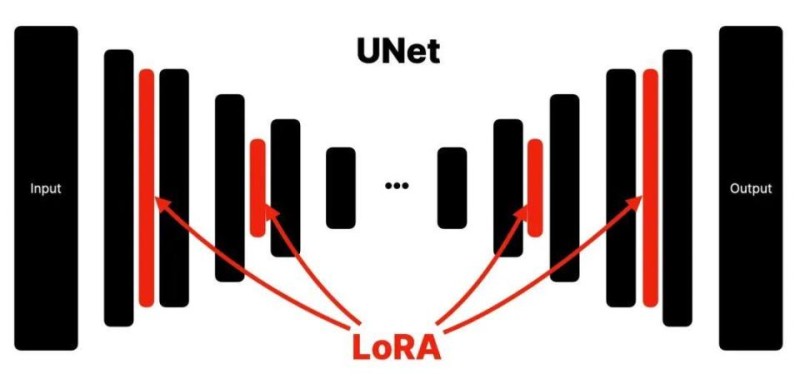
用类比来理解,可以将 LoRA 视为类似相机「滤镜」。
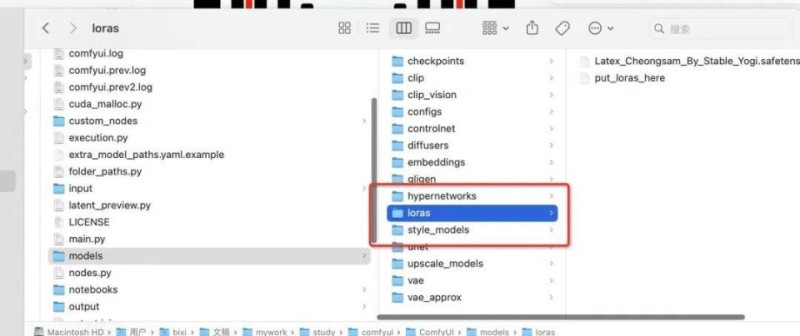
LoRA模型下载好后,放置在如下的目录里:
强大的ComfyUI不仅能支持文生图、图生图,还可以通过插件和Custom Node的引入,实现文生视频等复杂工作流。
2.2.1. 安装插件
我自己的使用过程中,安装了一些比较实用的插件,也推荐给大家。
首先cd到 custom_nodes 目录下,然后执行以下命令:
然后重新加载 ComfyUI的Web界面,会发现右侧的模块多了几个功能,此时就代表插件生效了:
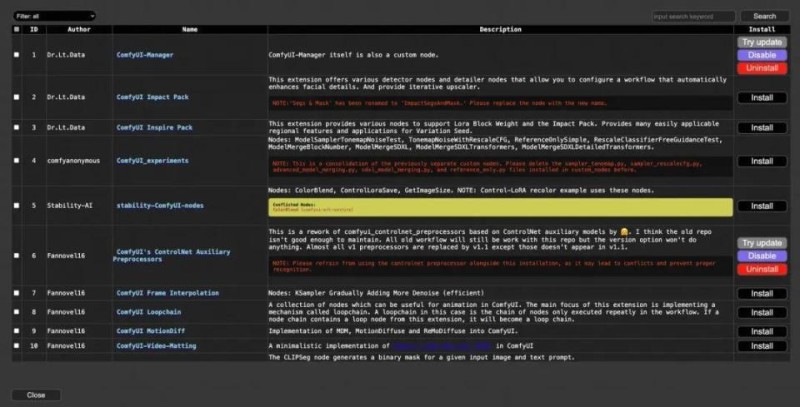
这个时候直接点击【Manager】,即可对ComfyUI进行可视化操作管理:
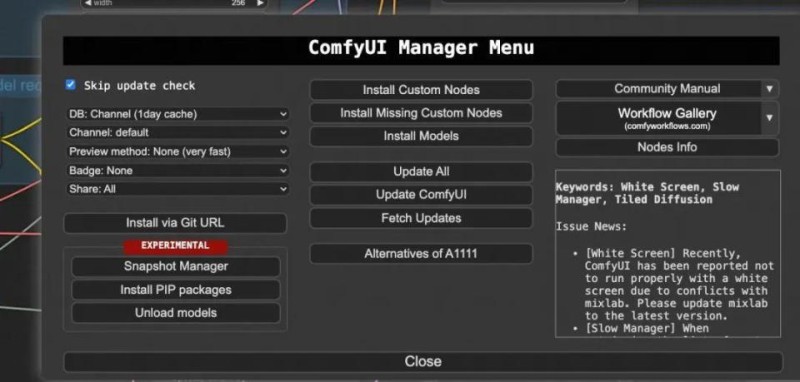
在这个界面下,可以进行Custom Node的安装升级,以及模型的下载等。
文生动图推荐一个插件:

也可以自己手动下载安装:
ComfyUI-AnimateDiff-Evolved:https://github.com/Kosinkadink/ComfyUI-AnimateDiff-Evolved
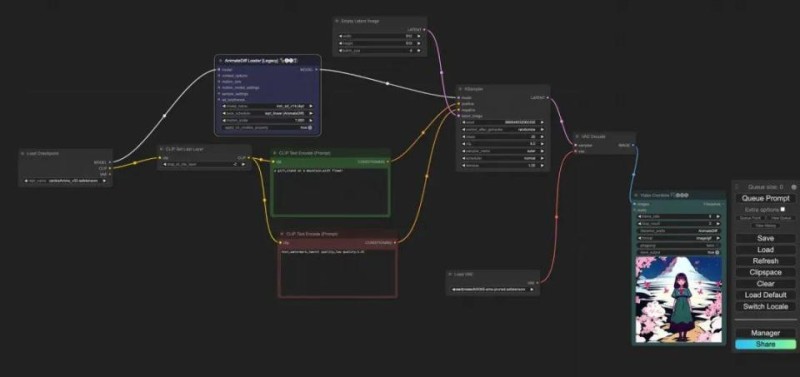
大致工作流如下:
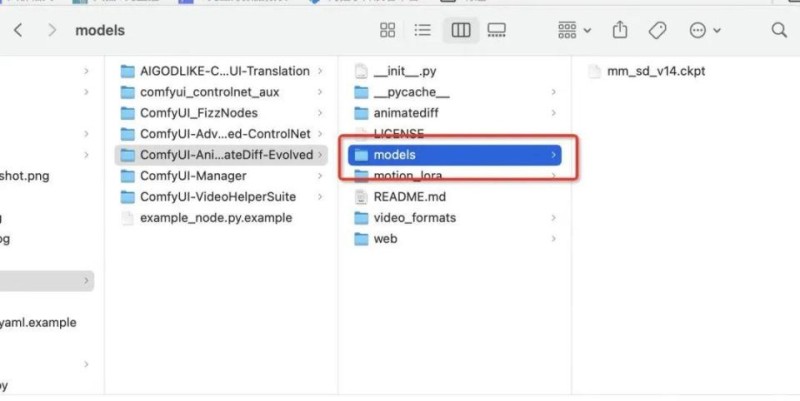
插件需要的模型,则安放在插件自己的目录下:
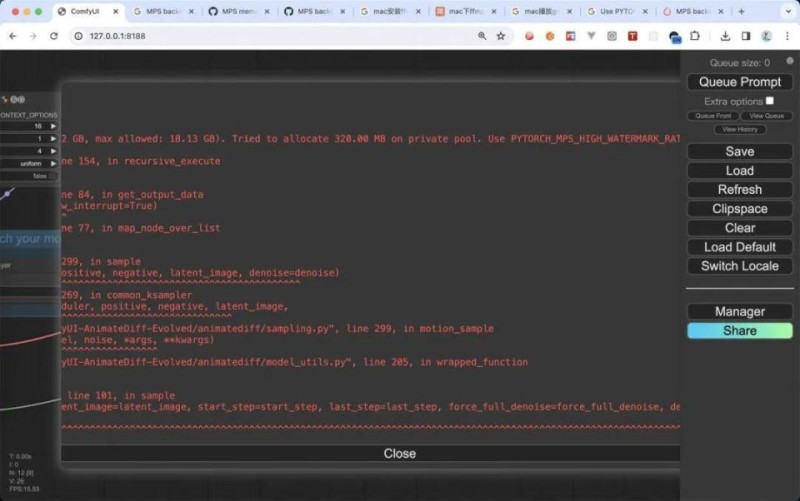
我这台电脑在batch_size 过高时候会爆栈,如果你的电脑性能更强劲的话,可以生产更好看的动图:
四、效果展示&工作流分享
1. 效果展示:文生图


2. 效果展示:文生动图
我的工作电脑只有 16 G内存,所以只能生成一些帧率不高效果一般的动图,大家可以换高性能电脑试试。
3. 工作流分享
五、一些总结
1. 关于环境
使用comfyUI或者跑一些demo的时候,建议用conda创建一个虚拟环境,这样你在进行一些python包安装的时候,会很大程度上去避免解决包冲突问题,这会让你少一些烦躁。
2. 关于使用插件遇到问题
3. 关于AI
很庆幸我们这样的工作,能够在第一线去体验AI给我们带来的惊喜和成果,也相信随着AI技术的发展,能让每个人都慢慢享受到AI技术进步带来的方便。
全面安全保障:等级保护合规解决方案
阿里云安全整合云平台等保测评经验和云安全产品优势,联合等保咨询、等保测评机构等合作资源,提供一站式等保测评服务,覆盖等保定级、备案、建设整改及测评阶段,助您快速通过等保测评。