不过在我们的测试中,也发现了涉及到账号登录、扫码登录的页面,GLM-PC没办法自主操作,也不会停下来,而是不停地重复该页面。
与Operator一样,GLM-PC也做了敏感性测试,让用户在敏感时刻,比如确认提交信息、确认支付等页面接盘操作。
同时,在GLM-PC操作电脑页面时,会由GLM-PC主导鼠标,人为干预后仍然继续GLM的流程,只能按下暂停键或结束键才能完全交予人类接管。
1
GLM-PC怎么做到的?
在技术路线上,GLM-PC与Operator采用的是同一种技术方案:基于多模态大模型的视觉识别与空间进行交互。
据OpenAI介绍,Operator基于最新研发的Computer-Using Agent (CUA) 模型,通过观察屏幕并使用虚拟鼠标和键盘来完成任务,而无需依赖专门的API接口。
早在2023年12月,智谱便发布了CogAgent,是其第一个基于视觉语言模型(Visual Language Model, VLM)的开源 图形界面智能体 GUI Agent 模型。GLM-PC即是基于该模型的初代产品。据开发文档中介绍,通过多模态感知实现全 GUI 空间交互。这些 GUI Agent,类似人类,能以视觉形式感知界面元素与布局,模拟人类进行点击、键盘输入等元操作,极大拓展了 Agent 在虚拟交互空间的应用边界。
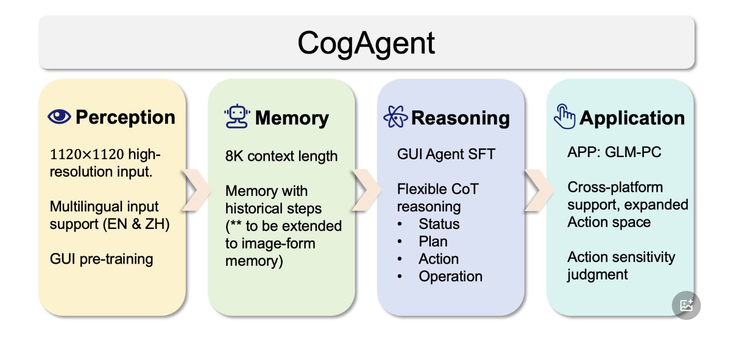
在GLM-PC 1.1版本中,使用更强大的视觉语言模型GLM-4V-9B作为基座模型,用来提升模型的基座图像理解性能。
与Operator相同的是,基于LLM模型提出Prompt,同时输入的模态(图像感知)、输出的操作空间(点击、滚动、键盘输入)的交互方式一致,同时思考了Agent和人类的使用权交接情况,对于敏感时刻的判断等等。
且在介绍中,Operator令Sam Altman颇为骄傲的是它的自我进化和自我反思能力,即Operator可通过不断操作和学习掌握人类的习惯,不断拓宽自身的能力边界。
GLM-PC也基于智谱自研的「基础智能体解耦合中间界面」和「自进化在线课程强化学习框架」,其中包括了一种核心技术WebRL,对于大模型智能体任务规划、训练任务和数据稀缺、反馈信号稀少和多任务策略分布等问题进行了有意识的对抗,加之自适应学习策略,能够在迭代过程中不断改进,持续稳定提高自身性能,并在执行过程中获取更多新技能。
不同的是,目前Operator现阶段仅针对Web端,并且与ChatGPT绑定付费,而GLM-PC是独立的App,可针对电脑进行操作(包括浏览器和电脑本地),同时手机可远程遥控操作电脑,并且完全免费。
从Operator的日志上看,Operator一次仅能执行单步的线性预测,和步骤执行,而GLM-PC具备多层级规划预测能力,并将CogAgent 多模态GUI Agent模型与 CodeGeex代码生成模型相结合,可实现复杂严谨的逻辑控制。
但GLM-PC也对于硬件端的算力储备有一定的限制,仅支持M系列的Mac电脑以及Windows10以上的系统。我们在M1芯片的MacBook Air上进行测试,整个过程中并未出现卡顿情况。
