在这个数字化时代,数据的获取成为了各行各业的重要组成部分。对于初学者而言,掌握如何获取这些数据是非常有用的技能。在本文中,我们将通过一个示例向你展示如何用Python进行房价数据的爬取。以下是整个过程的概述和详细步骤。
我们将用以下表格展示整个过程的步骤:
第一步:确定目标网站
在开始爬取数据之前,你需要确定你要爬取的目标网站。比如,我们选择一个常见的房地产网站,如“链家网”或“房天下”。
第二步:分析网页结构
使用浏览器的开发者工具(F12)查看网页的HTML结构,查找包含房价信息的标签。了解数据存储的结构对于编写爬虫至关重要。
第三步:安装必要的库
我们需要安装和库,以便能够发送请求并解析HTML文档。在命令行中运行如下命令:
第四步:编写爬虫代码
以下是一个基本的爬虫代码示例,它从一个假设的房价信息页面抓取房价数据。
第五步:运行爬虫并获取数据
确保替换了代码中的,然后在命令行中运行此Python脚本。检查控制台的输出,确认是否成功获取了房价数据。
第六步:数据清洗与处理
有时获取的数据可能不是我们想要的格式。我们可能需要对其进行清洗。例如,去掉多余的字符或将数据转换为数字类型。这段代码示例展示如何去掉价格中的“元”字符并转为数字。
第七步:数据可视化
最后,我们可以将数据可视化以便更直观的分析房价情况。以下是生成饼状图的Python示例代码。
使用语法的状态图可以描述爬虫状态:
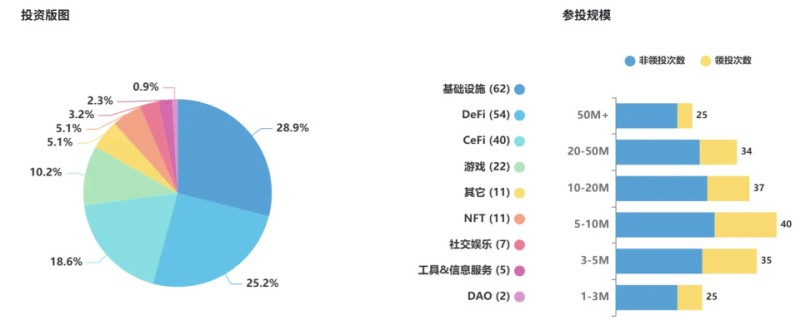
房价分布情况的饼图可以用如下方式表示: