地址来源多样化,可信度不同
客观联系
常住人口数据、流动人口数据······
政府公安
核酸疫苗、寄件物流、医社保······
业务办理
个人申报业务、旅游、医疗······
其他
出行登记等
人与地的关系是否匹配,得出匹配的标准地址(即人的实际生活的地址)
业务处理:关联、清洗、过滤、聚合、标准化
思路分析:
原始数据汇聚
原始地址标准化
人与标准地址关联
计算可信等级和分值
关联人机库
关联手机常住地址
手机地址匹配校验
原始数据汇聚
可信等级一 存在客观联系:如常口、流口、水电气宽带班里登记地址等——>数据清洗——>最早最晚时间
可信等级二 具有一定严谨性:如疫苗、交通、医保、社保等——>数据清洗——>最早最晚时间
可信等级三 可信度较低:个人申报地址,如旅游、医疗、个人登记等——>数据清洗——>最早最晚时间
通过打分后汇集为原始地址合表,可信等级一级打60分,可信等级二级打45分,可信等级三级打30分
原始地址标准化
通过原始地址合表关联标准地址表,得到标准化地址合表;将新原始地址配出掉已经存在的地址,通过清洗数据调用标准地址接口合并到标准化地址合表中。 新增完善标准地址数据
人与标准地址关联
标准化地址合表 字段:原始地址、标准地址(省、市、县、经纬度、管辖区域派出所等等)
人与标准地址关联表 字段:国家地区、证件号码、原始地址、首次采集时间、末次采集时间、可信等级、分值、数据来源名称
通过标准化地址合表,将标准地址拼接到原始地址合集中,得到人与标准地址关联表
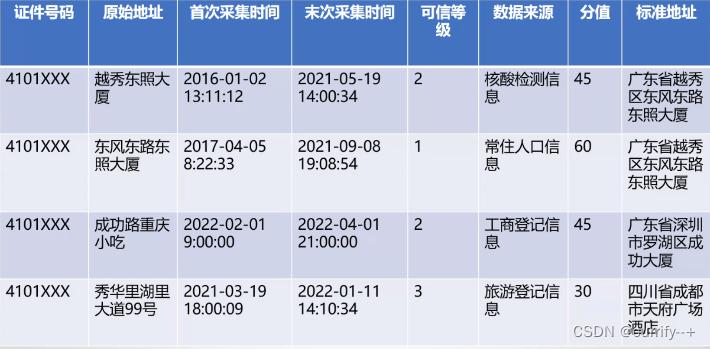 关联表示例
关联表示例
计算可信等级和分值
将人与标准化地址关联表,以证件号码标准化地址聚合,获取出最高等级数据、首末采集时间、来源资源个数,重新统计分值得到新人地关系表
重新计算可信等级:
1.距今三个月内的,而且采集次数大于等于3,可信等级上升1级
2.距今一年以上的,而且采集次数少于3,可信等级降低一级,例如3级降为4级的
计算分值:
1.可信等级对应的分值:1级60分,2级45分,3级30分,4级15分
2.本次采集时间的分值:40-25*本次采集时间距今天数/92,即每隔三个月则减2.5分。例如:本次采集时间为6.1,距今9.1相差32天,则本次采集时间的分值=37.5
关联人机库
通过新人地关系表,关联可信等级高的手机,得到人、机、地关联表
关联手机常住地址
通过人、机、地关联表,关联手机常住地,再加上手机常住地经纬度信息,计算标准地址与手机常住地地址距离,得到地址距离表
手机地址匹配校验
通过地址距离表,标识匹配结果,得到人地结果表

1.通过对不同来源的人地表进行数据的清洗
replace()
建模过程中,经常由于人为、客观因素导致数据错误,需要对数据的值进行修改,比如某个县撤县划区,户籍表需要将原来的县修改为区,那么需要使用值替换的函数replace()对相应的值进行修改
参数一:需要进行替换的字段,如证件号码(789456 198275 462981)
参数二:想要替换的内容,如想要替换证件号码中的' '
参数三:修改后的值
hive内置函数中与replace相似的用法
2.通过聚合函数找出该人地数据表最早最晚采集时间
3.因为数据表中可能会包含一些重复的数据,所以需要通过证件号加居住地两个字段进行去重,留下一条最近采集的数据
4.通过hive语句对该人地数据表进行可信等级的打标,以便后序的分值计算

正则表达式是对字符串操作的逻辑公式,利用事先定义好的一些特殊字符、及这些特定字符的组合,组成一个’规则字符串‘,这个’规则字符串‘用来表达对字符串的一种过滤
正则表达式的函数主要有:like、rlike、not like、regexp_extract、regexp、regexp_replace
常用正则表达式的元字符


hive正则表达式函数
1.like
形式:A like B,其中A是字符串,B是表达式,表示能否用B去完全匹配A的内容,B只能使用简单匹配符号_和%,"_"表示任意单个字符,字符"%"表示任意数量的字符
2.not like
形式:A not B;A like B两种用法一样,是like的否定用法,如果like匹配的结果是true,则not like的匹配结果是false,反之亦然
3.rlike
形式:A rlike B,表示B是否在A里面即可;而A like B,则表示B是否是A
B中的表达式可以使用正则表达式
4.regexp
形式:regexp的用法和rlike一样
5.regexp_replace
形式:regexp_replace(string A,string B,string C)
说明:将字符串A的符合Java正则表达式B的部分替换为C
6.regexp_extract
形式:regexp_extract(string A,string pattern,int index)
说明:A是需要处理的字符串,B是拆分的正则表达式,C是返回位置
1.距今三个月内的,而且采集次数大于等于3,可信等级上升一级
2.距今一年以上的,而且采集次数少于3,可信等级下降一级,例如3下降为4
3.重新计算分值: =可信等级对应的分值+末次采集时间的分值
1)可信等级对应的分值:1级等于60分,2级等于45分,3级等于30分,4级等于15分
2)末次采集时间的分值:40-2.5*末次采集时间距今天数/92(即每隔三个月则减2.5分),例如末次采集的时间为今年6月1号,距离今天9月1号相差92天,则末次采集时间的分值=37.5
标识与手机常驻地址匹配情况:
1.当距离小于等于1公里,标识为:完全匹配
2.当距离大于1公里小于5公里,标识为:部分匹配