先说结论,稠密算力和稀疏算力的关系基本是翻倍,单单评判算力的时候,至少需要区分是稠密还是稀疏。高通SA8650P的等效稀疏算力是200TOPS,英伟达Orin在运行LLM大模型时,只能用GPU,DLA加速模块无法使用,稀疏算力只有167TOPS,所以SA8650P更快。最新一代的至尊版SA8797P算力推测应该不低于700TOPS,GPU算力则明显SA839P7/SA8797P更高,CPU算力也是如此,存储带宽方面两者完全相同,基本上SA8797P整体性能略高于Thor-U;整体功耗方面,SA8797P大约70-80瓦,远低于Thor-U,散热成本会低不少。
下面一一展开,具体分析。
国内某知名方案商对高通SA8650P和英伟达Orin跑LLM大模型做了实际测试。
QNN是高通的神经网络引擎,MLC-LLM是英伟达特别为LLM设计的算子加速引擎。W4A16指权重使用4位整数量化,但是激活值仍然保留较高的精度,通常是使用16位浮点数(FP16)或者混合精度(Mixed Precision)。很明显SA8650P比Orin快20%,为何SA8650P会比表面算力更高的Orin更快?这是因为SA8650P的等效稀疏算力是200TOPS,英伟达Orin在运行LLM大模型时,只能用GPU,DLA加速模块无法使用,稀疏算力只有167TOPS,所以高通SA8650P更快。此外,LLM这种基于Transformer模型推理对纯GPU架构并不合适,效率较低,而SA8650P这种标量+矢量+张量的异构计算效率更高,因此总延迟时间更短。下文会详细说明,现在我们先说AI算力。
英伟达Orin的AI运算实际分三部分,一部分是DLA可以看作NPU,8位整数下是稀疏算力87TOPS。其GPU有2048个CUDA核心和64个张量核心,2048个CUDA是5.2TOPS@FP32算力,换8位整数下应该是20.8TOPS,64个张量核心只针对INT8精度,算力是62.7TOPS,合计就是83.5TOPS,英伟达又针对稀疏网络做了优化,声称算力可增加一倍,于是INT8精度下就是167TOPS,不过对于64个张量核心的算力,英伟达从未正式提及,这个62.7TOPS是我根据英伟达的算力值倒推出来的。
AI运算的流程是这样的,CPU作为Host,用标量取址然后译码,然后判断指令类型,是矢量计算就绑定线程送入矢量计算单元,是矩阵运算就送入张量计算单元即NPU。但是英伟达的DLA只受PVA控制。虽说PVA可以和CPU并发通信,但PVA不能等同CPU,并且PVA定位是主要做矢量运算的,控制流主要还是标量计算。
图片来源:英伟达
上图是英伟达Orin-X的内部框架图,可以看出DLA是挂在PVA上的,且只和PVA有联结。
英伟达DLA内部框架
图片来源:英伟达
图片来源:英伟达
上图是英伟达PVA的内部框架图,综合来看,CPU、GPU、PVA和DLA都有独立的存储系统,数据需要频繁地搬运,效率大打折扣。PVA内部是一个双7路(slot)的VLIW矢量处理器,双直接存储接入DMA。
为什么要在DLA上加一个PVA,因为DLA是一个固定功能的NPU,英伟达的技术手册是这么说的,The NVIDIA Deep Learning Accelerator, or DLA, is a fixed-function accelerator optimized for deep learning operations. It is designed to do full hardware acceleration of convolutional neural network inferencing.这是一个卷积神经网络推理的全硬件加速器,换句话说就是完全没有编程能力,完全没有灵活性,PVA就像是DLA的Host,DLA是一个外设,是Devices。它只能做卷积运算,而LLM/VLM/VLA时代,从头到尾都是transformer架构,根本没有DLA用武之地,LLM/VLM/VLA时代英伟达Orin-X的稀疏算力值只有167TOPS,那如果是包含卷积的传统算法时代呢,由于数据需要频繁地搬运,效率大打折扣,Orin-X的稀疏算力值估计也只有200TOPS或略高。当然,成本限制,高通SA8650P的存储带宽低于Orin-X。此外,英伟达依靠CUDA生态系统,在编译器效率方面有优势。
Jetson Thor 架构
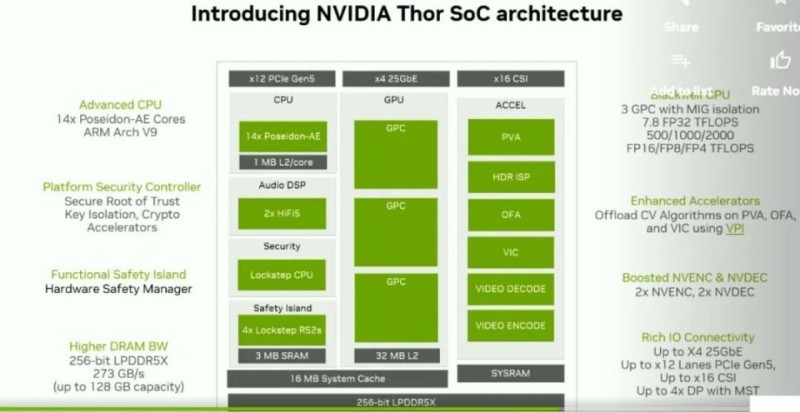
图片来源:英伟达
在GTC 2025大会上截图,英伟达干脆在Thor上取消了只能做卷积运算的DLA,这也反证了DLA只能做卷积运算,在LLM/VLM/VLA时代没有用武之地。
再有就是去年10月发布的高通骁龙汽车平台至尊版即SA8397P和SA8797P,SA8397P主打座舱,SA8797P主打ADAS,其中SA8797P可以做舱驾一体。以前高通在ADAS领域主打性价比,从至尊版开始主打性能。根据产业链厂商的信息,主打座舱的SA8397P在INT8精度下稠密算力就是320TOPS,稀疏算力翻倍,有640TOPS。
在高通骁龙汽车平台至尊版之前的高通汽车芯片,其Hexagon HTP或者说NPU架构都是通用的,即手机、汽车、工控和笔记本电脑。但是骁龙汽车平台至尊版芯片的NPU架构是全新设计,只为汽车领域设计,不仅算力超高,且符合ASIL-B安全认证,这就是V83和V85架构,高通官方没有提供任何有关V83/V85的信息。本文有关信息来自https://s.itho.me/ccms_slides/2025/4/23/17fd0f77-3df3-4925-8a0c-0a0e853f331c.pdf,PDF的名称为《嵌入式車用 GenAI 成本、代价与信息安全风险》
数据来源:网络,佐思汽车研究整理
英伟达车载芯片参数一览
数据来源:网络,佐思汽车研究整理
AI算力方面,SA8397P/SA8797P和目前最先量产的Thor-U算力差不多,SA8797P算力应该不低于700TOPS,毕竟主打座舱的SA8397P都有640TOPS算力,GPU算力则明显SA8397P/SA8797P更高,CPU算力也是如此,存储带宽方面两者也是完全相同,都是256 bit LPDDR5X,即273GB/s。基本上SA8797P整体性能略高于Thor-U。不过整体功耗方面,SA8797P大约70-80瓦,远低于Thor-U,散热成本会低不少。
稠密和稀疏的关系基本是翻倍,在神经网络中,运算中的权重有高达70%可能是零。这些零值矩阵不仅占据了大量的存储空间,还增加了计算的复杂度,降低了计算效率。因此,英伟达提出了稀疏算力技术,通过硬件优化来专门解决这一低效问题。此功能是由稀疏 Tensor Core 提供,这些稀疏 Tensor Core 需要 2: 4 的稀疏模式。也就是说,以 4 个相邻权重为一组,其中至少有 2 个权重必须为 0,即 50% 的稀疏率。稀疏 Tensor Core 在执行矩阵乘法时仅处理非零值,理论上,计算吞吐量是同等稠密矩阵乘法的 2 倍。也就是说它只能对应50%这一种稀疏度,要想支持其他的稀疏度就得改变权重组的大小和组内非零权重的数量。这样很可能严重影响模型的精度,50%这种稀疏度是很难做到的,通常剪枝最多做到60%的稀疏度,模型越大,稀疏度越难降低。
稀疏网络增强并非是英伟达独有的,高通和地平线也在2022年左右开始支持稀疏网络增强,国内地平线的旗舰J6P算力是560TOPS,地平线发布会上严谨地做了标注,560TOPS是在1/2稀疏网络下的等效算力。英伟达的算力一般默认都指稀疏算力。高通和华为默认是稠密算力。
高通Hexagon V73的前端
图片来源:https://chipsandcheese.com/p/qualcomms-hexagon-dsp-and-now-npu
很明显,它包含4个标量线程,6个矢量线程,1个矩阵张量线程,采用一个4槽的VLIW架构。标量线程可以简单看做CPU,矢量线程可简单看成GPU,矩阵张量线程可以简单看做NPU或TPU。他们都在统一的紧耦合存储系统内,避免了数据的频繁搬运,效率得到提高。
此外图上明确标注了16K的MAC阵列,年轻一代消费者买车时更在意汽车的科技先进程度,而算力数值是最简单衡量科技先进程度的数值,消费者不是业内人士,只看AI算力值,这就使得从芯片厂家到整车厂都在算力值上下功夫,算力数字游戏大行其道。说个完全无法注水、最真实的算力衡量方式,那就是MAC阵列数量,MAC即乘积累加,深度学习或者说AI运算最核心的计算就是矩阵的乘积累加,MAC阵列一个周期能完成两次操作Operations,算力值就是MAC阵列数量*2*MAC阵列运行频率,例如高通V73 NPU有16K MAC数量,运行频率峰值1.5GHz,算力值就是16K*2*1.5GHz=48TOPS,每秒48万亿次操作。再比如英特尔的Lunar Lake NPU,是Intel的第四代NPU,支持fp16和int8数据类型,单Neural Compute Engine(NCE) 包含2K个 int 8 MACs 一共有6 NCEs,算力就是12K MACs per cycle,NPU对外提供的int8算力就是12000*2*2.05GHz =48TOPs。谷歌TPU V1有65K个MAC,频率为700MHz,算力即为65000*700MHz*2=91TOPs。
高通SA8397P的NPU采用4核心张量,简单说就是4个NPU,之前的架构都是单核心。同时采用最先进的3纳米工艺,晶体管密度更高,意味着可以在同样面积同样成本下放入更多的MAC计算单元,每个张量核心有24K的MAC阵列,4个就是96K阵列,NPU的运行频率一般在0.8-1.7GHz之间,INT8位稠密算力即96000*2*1.7GHz=326.4TOPS。
CNN时代,AI加速器通常只负责矩阵乘法加速,也就是张量Tensor处理器,CNN的计算逻辑非常简单,纯张量处理器足够应付。Transformer时代则不同,Transformer脱胎自RNN,虽然Transformer的训练有一定的并行性,但推理不同,有着明显的串行属性,控制逻辑复杂很多,同时,也有大量的矢量与矩阵的乘法运算,因此纯张量处理器完全不够用,需要加入针对标量Scalar运算器和Vector向量运算器。标量单元用于控制计算流、计算内存地址和系统级任务配置和下发。矢量单元用于一般计算,例如函数激活和 softmax。谷歌自第二代TPU开始配备矢量单元,三代TPU开始配备标量单元,亚马逊的AI芯片Inferentia第一代就加入了标量单元和矢量单元。META即FACEBOOK的第一颗芯片MITA V1则是两个RISC-V标量核心以及矢量核心和张量核心。标量、矢量和张量三者统一在一个计算体系内具备最高效率。
标量处理器的加入,让高通的Hexagon NPU灵活性大增,无论将来出现什么样的大模型架构,标量矢量张量三者配合都能胜任。同时异构计算体系的效率和性价比远胜纯GPU体系,这是因为GPU的架构为简化控制逻辑,大量使用寄存器,寄存器每个SM(流多处理器)有上千个寄存器,以Orin-X为例,有8192个寄存器,高通NPU异构计算体系CPU架构的寄存器数量通常是64个,庞大的寄存器数量意味着芯片面积很大,成本很高,功耗很高。
骁龙汽车平台至尊版的出现,意味着高通从主流ADAS市场,迈向高端市场,英伟达将迎来强劲对手。