任意打开一个小红书笔记的评论,打开浏览器的开发者模式(F12),选择网络,Fetch/XHR,找到目标链接的预览数据,经过我的实际测试,请求头包含User-Agent和Cookie这两项,即可实现爬取。其中,Cookie很关键,需要定期更换。那么Cookie从哪里获得呢?方法如下:
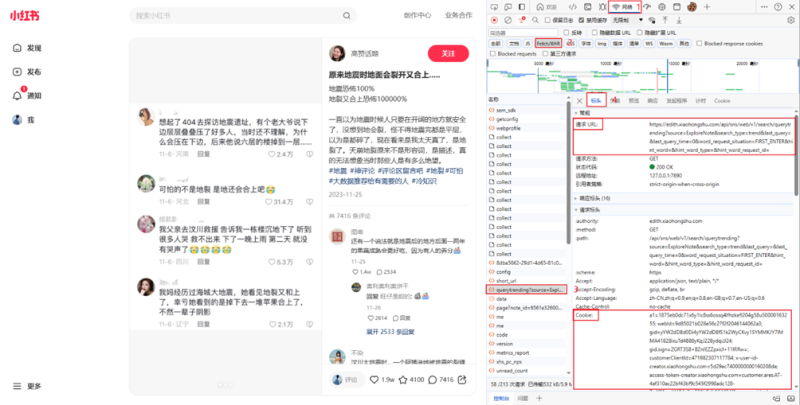
图2 小红书网页分析
从上图我们即可得到该网页的URL和Cookie,那么接下来即可对其评论进行分析,查找如何可以爬取一级后的评论。下面,开发翻页逻辑。
由于我并不知道一共有多少页,往下翻多少次,所以采用while循环,直到触发终止条件,循环才结束。那么怎么定义终止条件呢?我注意到,在返回数据里有一个叫做"has_more"的参数,大胆猜测它的含义,是否有更多数据,正常情况它的值是true。如果它的值是false,代表没有更多数据了,即到达最后一页了,也就该终止循环了。
另外,还有一个关键问题,如何进行翻页操作,实现对所有评论的爬取。
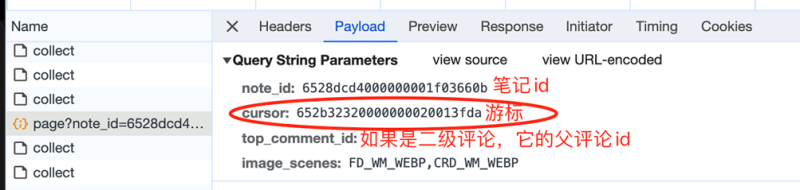
图3 cursor分析
这里的游标,就是向下翻页的依据,因为每次请求的返回数据中,也有一个cursor,大胆猜测,返回数据中的cursor,就是给下一页请求用的cursor,如下图4。
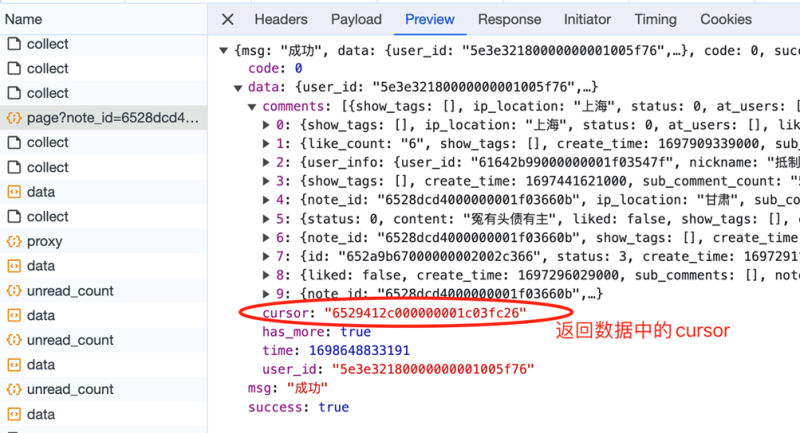
图4 下一页请求cursor分析
经过分析,返回数据中有个节点sub_comment_count代表子评论数量,如果大于0代表该评论有子评论,进而可以从sub_comments节点中爬取二级评论。其中,二级展开评论,请求参数中的root_comment_id代表父评论的id,其他逻辑同理,不再赘述。
导入项目所需依赖包。
2.1 Cookie和id的提取
根据浏览器前端内容,定义所需的变量,包括User-Agent和Content-Type、Cookie、Referer
Red_Booklet_id 以及host 。
2.2 文件命名及保存
定义函数将给定的毫秒时间戳转换为指定格式的时间字符串,使用time模块的localtime和strftime函数来实现,localtime函数将毫秒时间戳转换为本地时间,然后使用strftime函数将时间按照指定格式转换为字符串。默认格式为"%Y-%m-%d %H:%M:%S",可以使用其他格式,最后将转换后的时间字符串返回,用于我们对创建csv文件进行时间命名。
定义函数将给定的数据列表写入到一个CSV文件中,使用Python内置的csv模块来创建一个writer对象,并将数据逐行写入文件,函数使用“a”模式打开文件,表示追加模式,如果文件不存在则创建,函数通过迭代给定的数据列表,并将每个子列表作为一行写入文件。
2.3 获取二级评论
创建一个用于获取指定笔记的二级评论的函数,函数的参数包括笔记ID、页码、根评论ID和游标,函数通过调用HTTP GET请求获取二级评论的数据,并解析返回的JSON响应,然后,它会将每个二级评论的相关信息提取出来,并存储在一个列表中。最后,它将列表保存到CSV文件中。如果数据中没有更多二级评论了,则函数返回,否则,函数会更新游标,并递归调用自身以获取下一页的二级评论,如果在获取二级评论的过程中出现异常,函数会打印异常信息。
2.4 获取评论
下面函数,用于获取指定note_id的评论数据,函数通过调用API请求,获取一页一页的评论数据,并将每页的评论数据存储到CSV文件中。
2.5 保存评论
我们利用上述函数对小红书网页笔记进行爬取评论,然后讲爬取的数据保存到以当前时间命名的csv文件中,具体如下:
经过上述操作,我们即可对特定小红书笔记中的评论内容进行爬取。
参考文件:
Python爬虫实战:爬取小红书去水印图片_小红书爬虫-CSDN博客
